Documentation
SimScale leverages Physics AI in a cloud-native simulation environment to accelerate computational engineering. This documentation explains how to train simulation models using Artificial Intelligence – AI and how it could benefit users and engineering organizations with faster result prediction in seconds instead of actually simulating.
Consider the following AI trained example model of a Centrifugal pump. Running over hundreds of parallel simulations with geometry variations in the number of blades, blade thickness, etc. and variable inlet flow rates predicted CFD results within seconds for new user inputs with accuracy up to 99% and above.
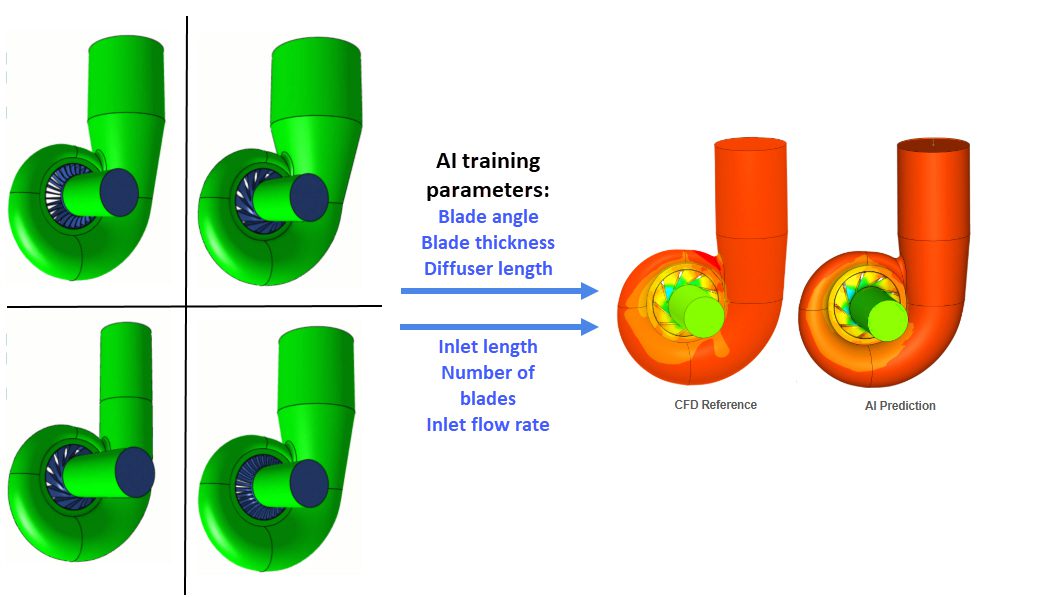
To do engineering simulations with AI, you need quick and easy access to models and data. SimScale’s cloud-based setup and well-organized simulation data storage make it super easy to use powerful AI tools whenever you need them. There are four major steps involved:
If your organization has a license for AI training then as an organization admin you can activate AI training permission for your users. This can be done by first accessing the ‘Manage users’ item on your Dashboard and then enabling the feature ‘AI training permission’ for each user individually.
Once the feature is activated, a new item AI Model Training can be seen in the left panel in the Dashboard.
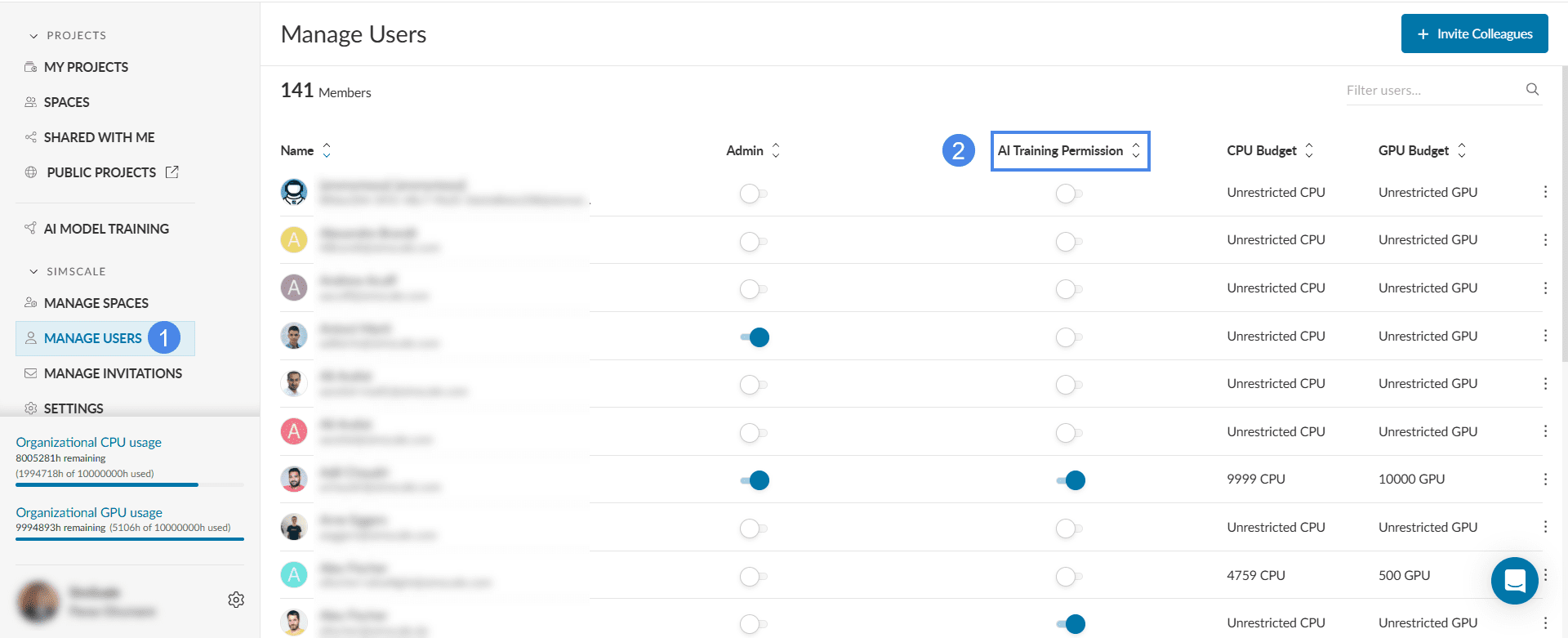
As an organization admin, you can access all the AI models created within your organization. This includes seeing them on the AI Models Training overview page as well as opening and editing each model individually.
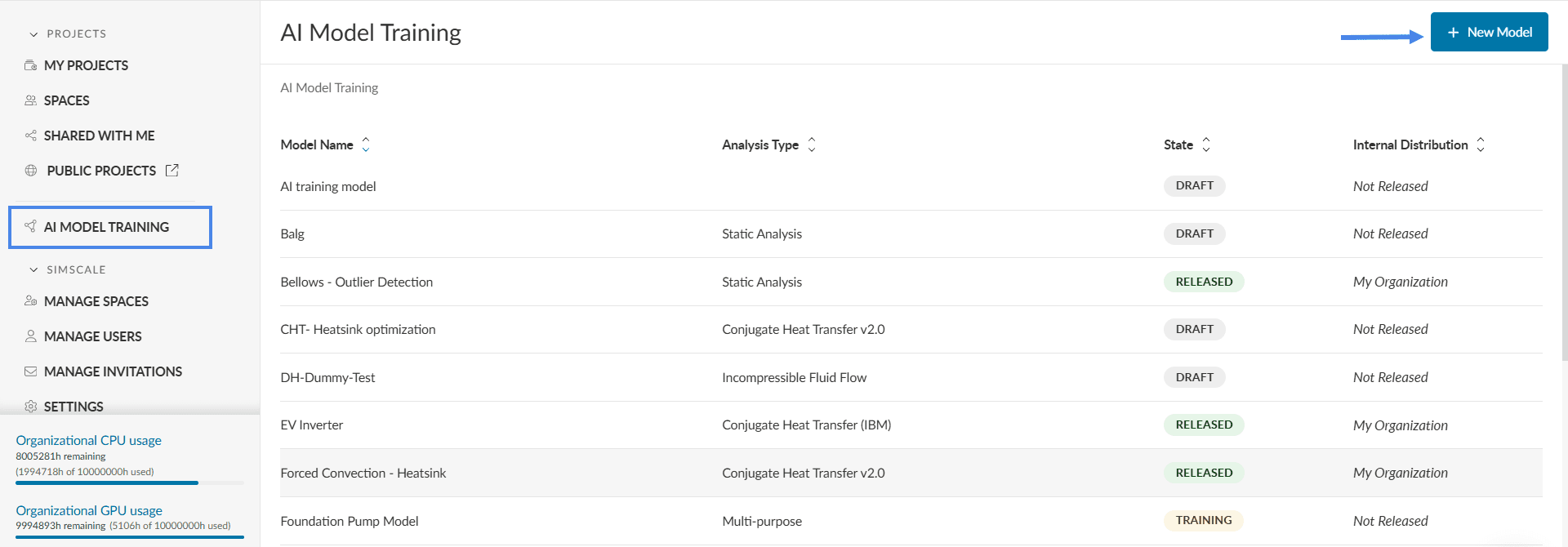
In order to train a new AI model, go to the AI model training page (see left menu in Figure 2) and click on the top right button ‘+ New model’.
Set a model name and description.

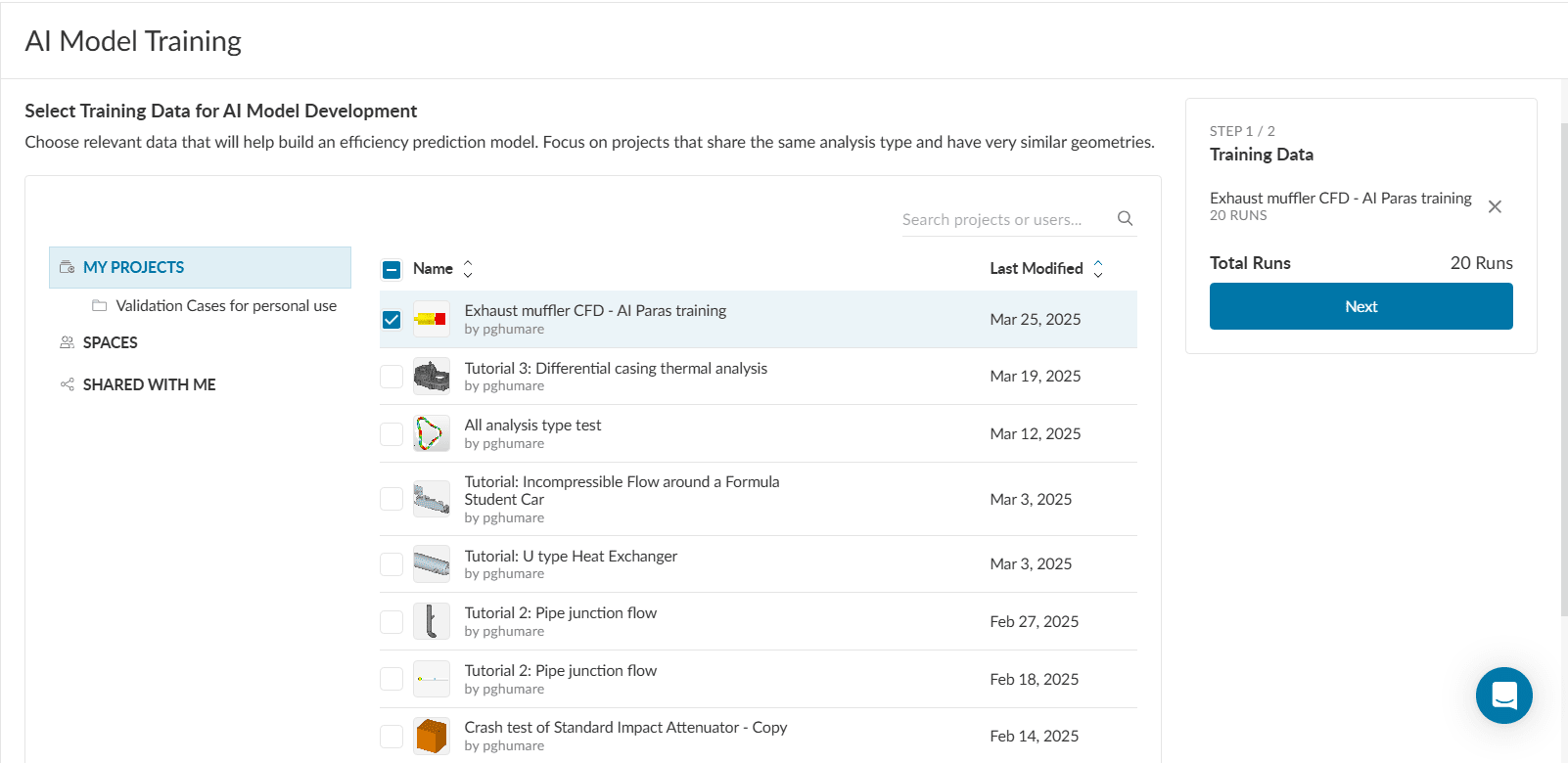
Proceed using the ‘Select Training Data’ button.
Select projects whose simulation data shall be used for AI training.
You need at least 20 simulation runs performed in a single project or across multiple projects, however, more data usually leads to higher AI model prediction accuracy.
Currently, the following analysis types are available for the AI model training:
The AI training is restricted to using simulation runs from only a single analysis type. If simulation runs from multiple analysis types have been completed in the selected projects, one has to be chosen.
Select ‘Next’ to choose an analysis type.
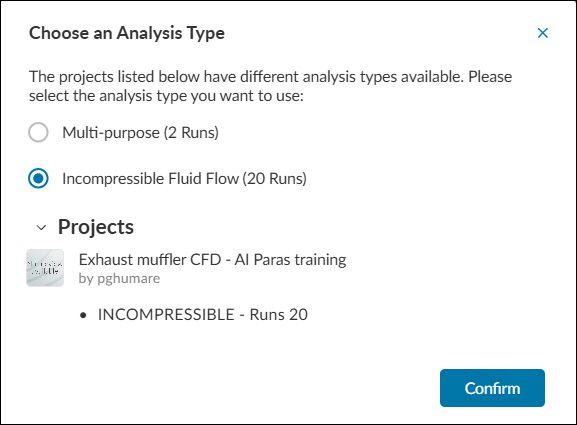
Select the analysis type of interest to display the corresponding projects. Click ‘Confirm’ to proceed.
Best Practices on How to Choose a Model for AI Training
There are mainly two parameters that can be varied:
In this step, some information related to the AI model training needs to be provided before it can be started.
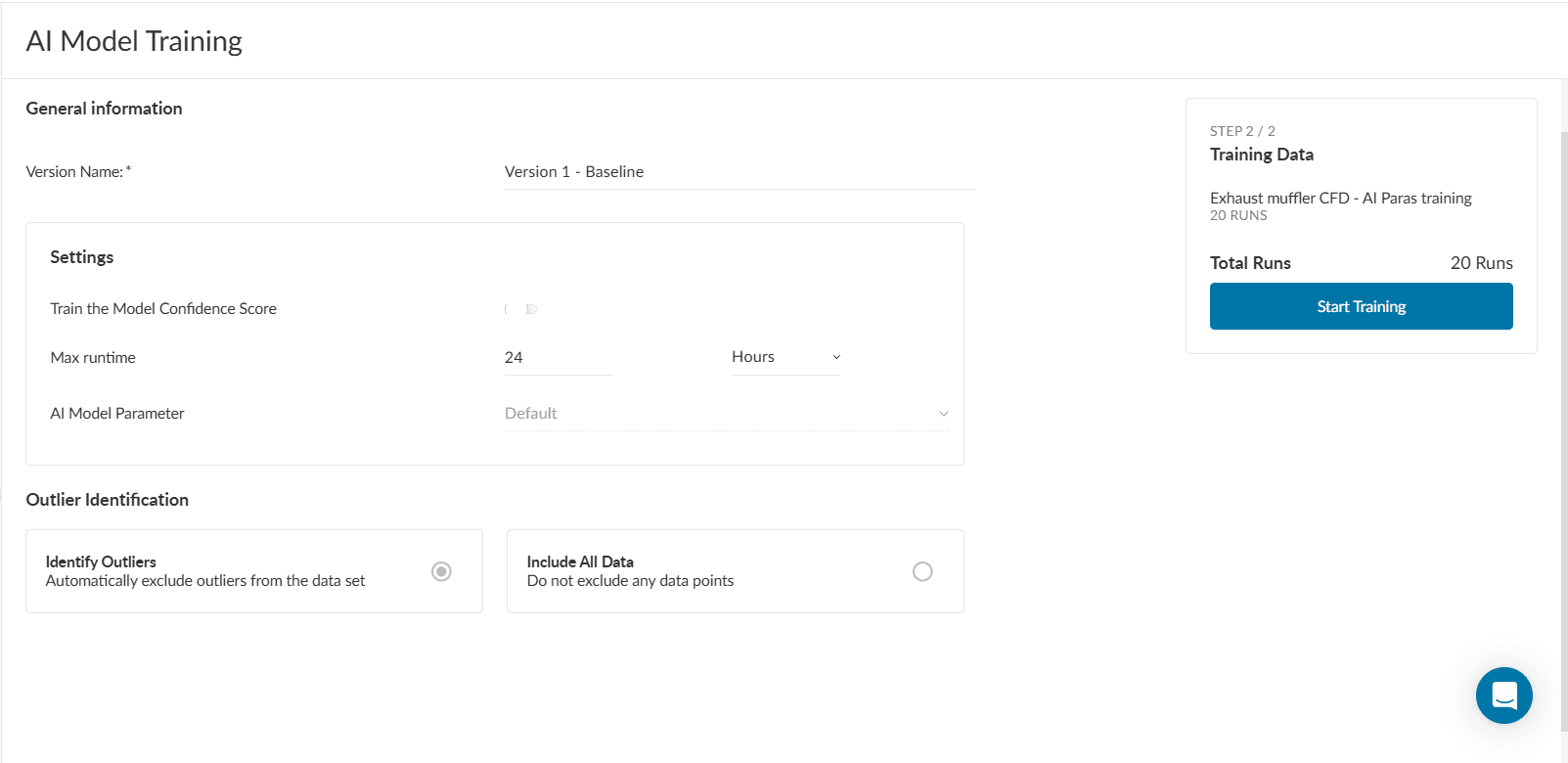
The required information is as follows:
The training status is displayed as follows:
Note
Currently, SimScale AI models can provide result predictions for all surfaces of the CAD, for e.g. pressure and velocity at inlet outlet and also on walls. If you want to train an AI model to predict also scalar values (like averaged pressures across a surface, drag coefficients, reaction forces, etc.) or restrict the training only to specific regions of the CAD please contact our support for assistance.
Before the AI model can be released for use by the organization, the following parameters should be thoroughly investigated.
Here, quality metrics for the quantities involved in the simulation, like velocity, pressure, etc., can be explored.
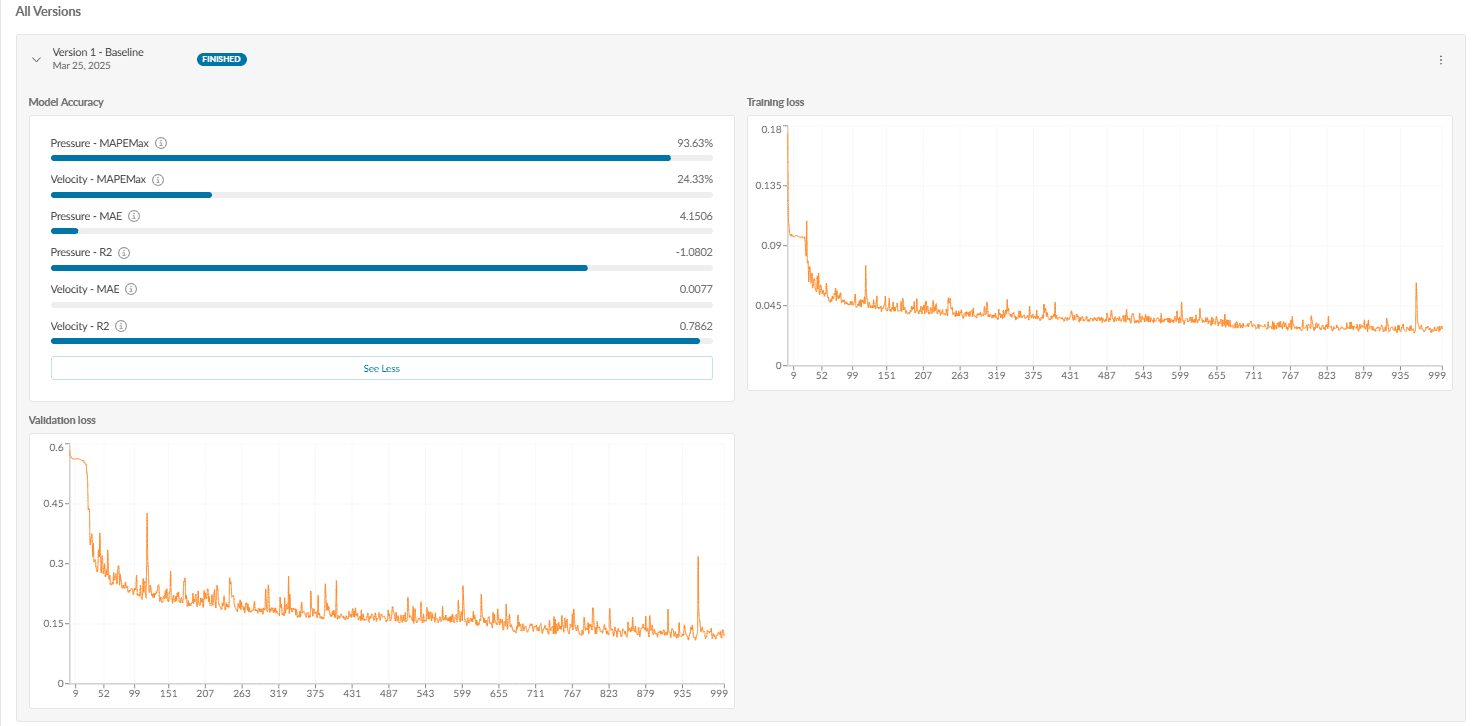
Mean absolute percentage error maximum. This should be close to zero.
Mean absolute error. This should ideally be zero. These are absolute values with units of the physical quantity involved.
R-squared coefficient. A value close to 1 indicates perfect accuracy.
Let’s understand the metrics using the figure above. The MAEPMax for pressure is 93.63 %; however, for velocity it is under 24.33 %. This means the AI model can be used for predicting velocity values with a lower degree of error.
The graph shows how relatable the data is. The loss should tend to zero and be significantly reduced on the last iterations compared to the initial value of the residual at iteration 0. One must be cautious not to run the AI training across too many iterations as this could bear the risk of overfitting the model to the training data. This means it would be difficult for the model to generalize beyond the given training data points, even for input data that is not too far from the training data.
In order to check that the model is not over-fitting to the training data, one must ensure that the training loss and the validation loss are in the same ranges – so the value of the validation loss over the last iterations should be close to the training loss. If the validation loss is much higher than the training loss, this is a strong sign of over-fitting, and a new training should be started with either more training data or training for fewer iterations.
If you are not satisfied with the training or if the current version did not finish successfully a new version can be trained. Additionally, a document can be created to provide key information for the users of this AI model. These two options are depicted in Figure 10.
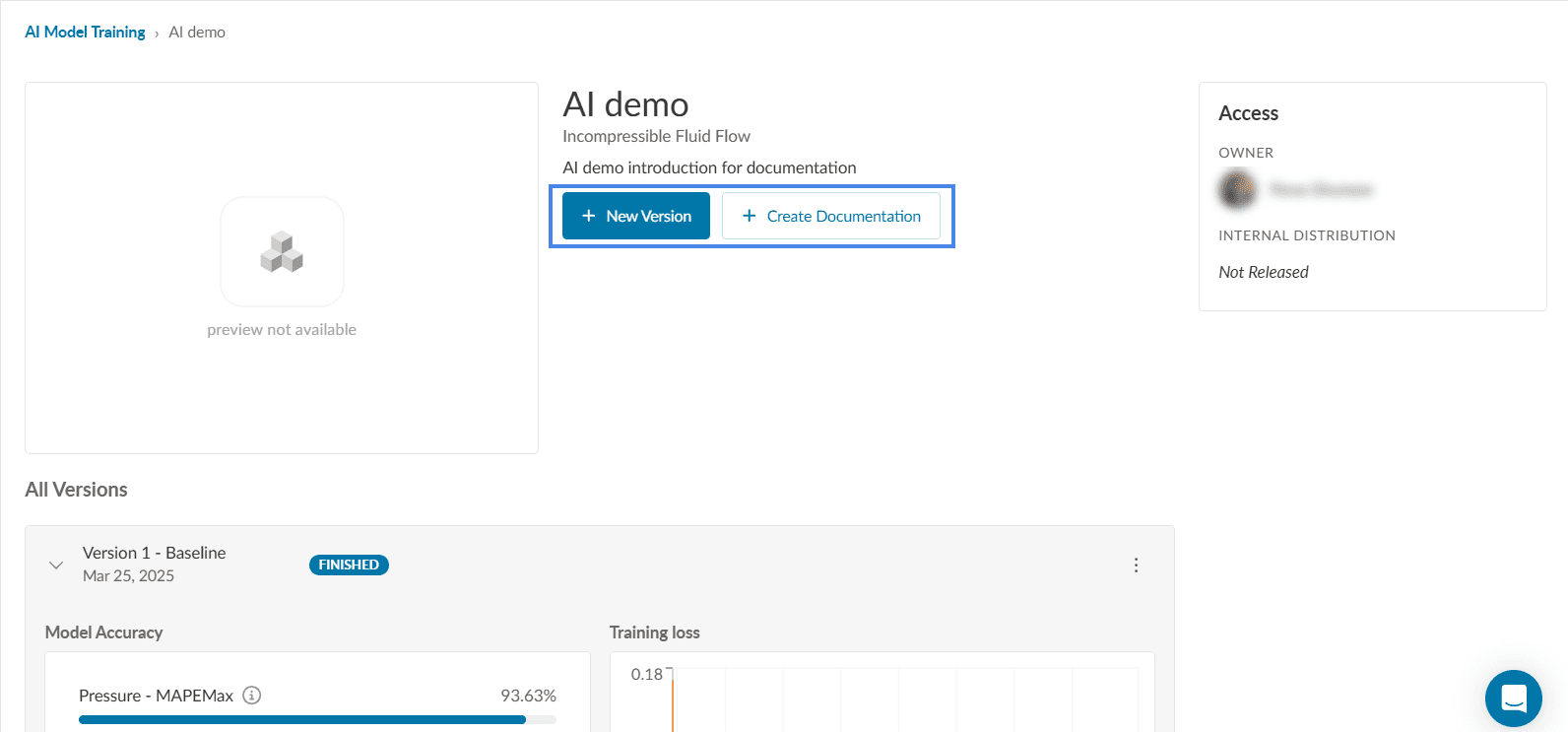
Once you are satisfied with the AI model training parameters, you have the option to release the trained model to users within your organization.
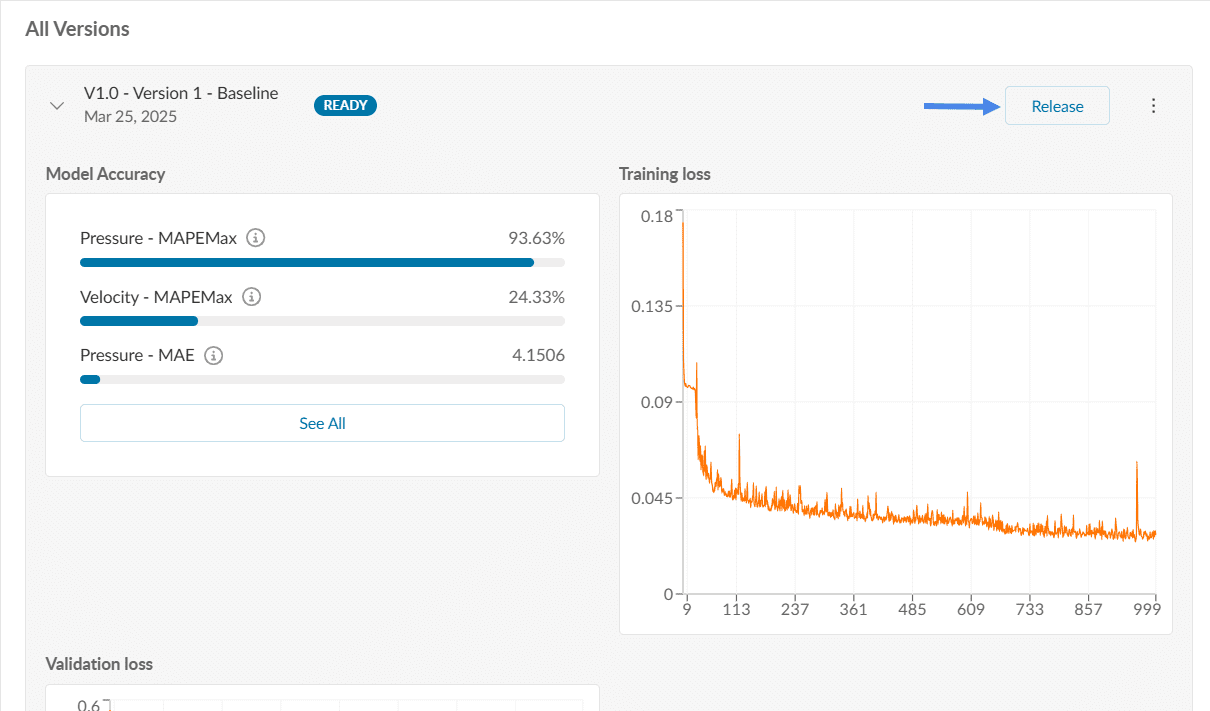
Click on ‘Release’. This opens a dialog box as shown below:
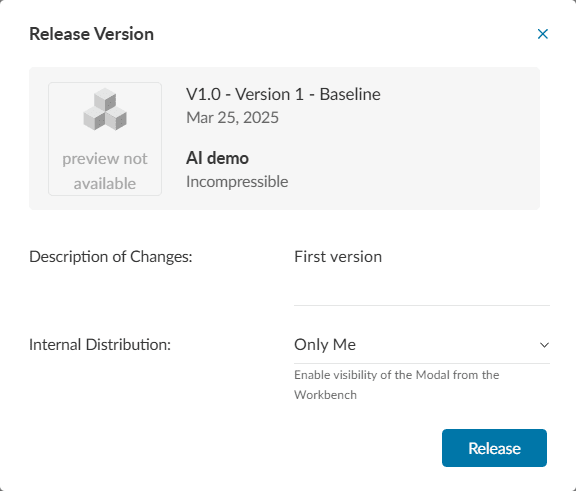
Click ‘Release’ again and a message that the version has been successfully released will be displayed.
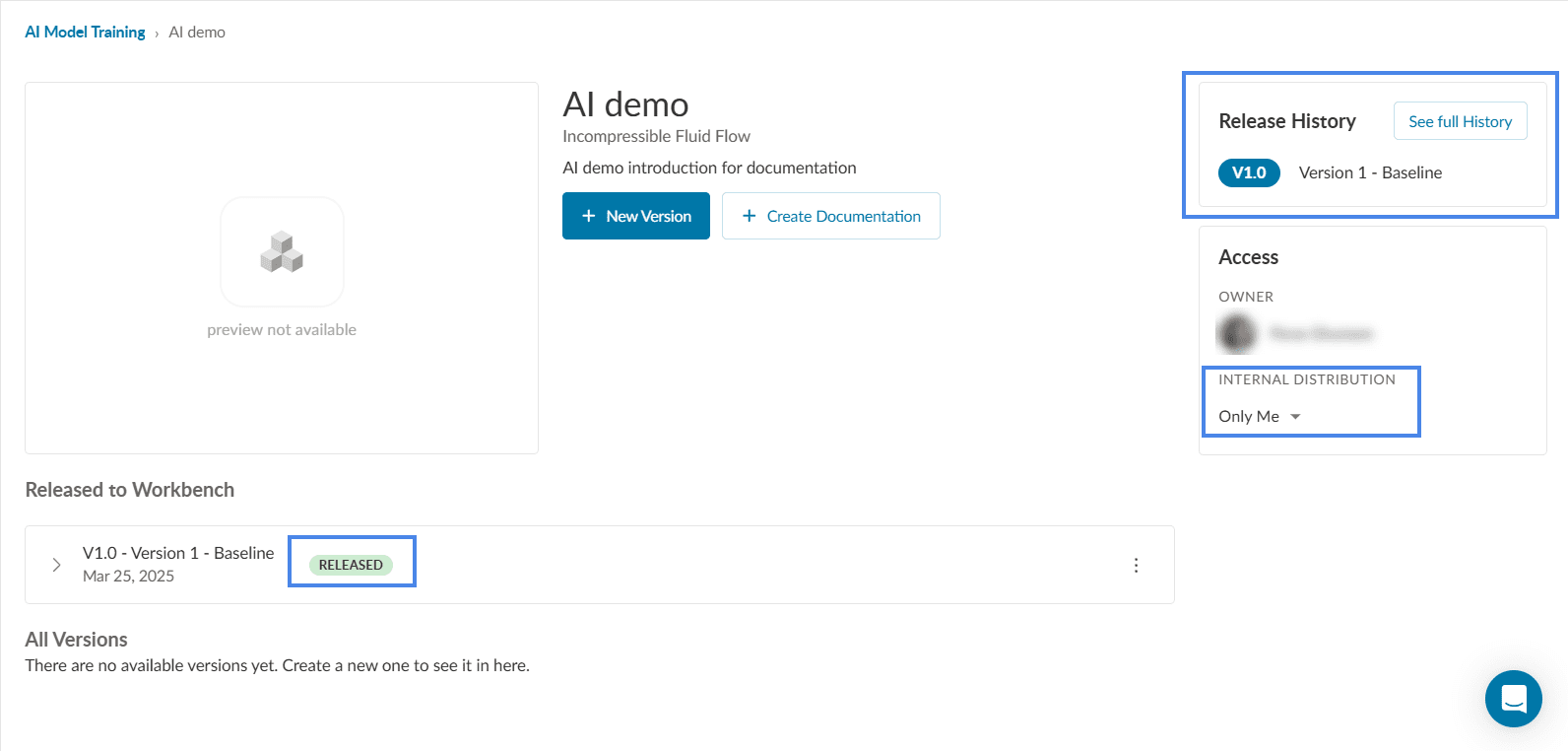
Once the trained model version is released to Workbench the AI Model Training page shows the release status and the type of internal distribution.
Last updated: April 23rd, 2025
We appreciate and value your feedback.
Sign up for SimScale
and start simulating now